우리가 파이썬 기반으로 정형 데이터를 구현한다고하면 대부분 사이킷런 라이브러리 패키지를 씁니다.
사이킷런이 이렇게 가장 인기가 많은이유는 다음과 같습니다.
- 파이썬 기반의 다른 머신러닝 패키지도 사이킷런 스타일의 API를 지향할 정도로 쉽고 가장 파이썬스러운 API를 제공합니다.
- 머신러닝을 위한 다양한 알고리즘과 개발을 위한 편리한 프레임워크와 API를 제공합니다.
- 오랜 기간 실전 환경에서 검증됐으며, 매우 많은 환경에서 사용되는 성숙한 라이브러리입니다.
- 앞서 본 Numpy와 Scipy 기반 위에서 구축된 라이브러리입니다.
사이킷런을 이용하여 붓꽃(Iris) 데이터 분류(Classification)
머신러닝계의 Hello World같은 붓꽃 데이터 분류를 하겠습니다.
붓꽃 데이터 예측 모델을 만들건데, 붓꽃 데이터의 피처(feature)는 Sepal lengh / Sepal width / Petal length / Petal width 이렇게 4개가 있습니다. (Sepal : 꽃받이 , petal : 꽃잎)
위와 같은 피처들의 값이 여러가지 있을텐데 이 피처값들을 기반으로해서 데이터 학습을 하고붓꽃 데이터의 품종을 Setosa, Vesicolor, Virginia 중에서 어떤 품종인지를 예측하는 머신러닝을 만들겠습니다.
머신러닝을 위한 간단한 용어
피처(Feature)
: 피처는 데이터 세트의 일반 속성입니다.
머신러닝은 2차원 이상(컬럼 속성)의 다차원 데이터에서도 많이 사용되므로 타겟값을 제외한 나머지 속성들은 피처로 지정됩니다.
레이블, 클래스, 타겟(값), 결정(값)
피처에 기반으로 패턴을 학습하게되어 결정된 값(타겟값)이 분류의 경우에는 레이블(라벨) 또는 클래스를 붙인다는 말을 씁니다.
타겟값 또는 결정값은 지도 학습 시 데이터의 학습을 위해 주어지는 정답 데이터를 의미합니다.
지도학습 중 분류의 경우에는 이 결정값을 레이블 또는 클래스로 지칭합니다.
지도학습 - 분류
분류(Classification)는 대표적인 지도학습(Supervised Learning) 방법의 하나입니다. 지도학습은 학습을 위한 다양한 피처와 분류 결정값인 레이블 데이터로 모델을 학습한 뒤, 별도의 테스트 데이터 세트에서 이미지의 레이블을 예측합니다.
따라서 지도학습은 명확한 정답이 주어진 데이터를 먼저 학습한 뒤 미지의 정답을 예측하는 방식입니다.
이 때 학습을 위해 주어진 데이터 세트를 학습 데이터 세트, 머신러닝 모델의 예측 성능을 평가하기 위해 별도로 주어진 데이터 세트를 테스트 데이터 세트로 지칭합니다.
위와 같은 방법으로 붓꽃 데이터 분류 예측 프로세스는 다음과 같습니다.
1. 데이터 세트 분리 : 데이터를 학습 데이터와 테스트 데이터로 분리합니다.
2. 모델학습 : 학습 데이터를 기반으로 ML 알고리즘을 적용시켜 모델을 학습시킵니다.
3. 예측 수행 : 학습된 ML 모델을 이용해 테스트 데이터의 분류(즉, 붓꽃 종류)를 예측합니다.
4. 평가 : 이렇게 예측된 결과값과 테스트 데이터의 실제 결과값을 비교해 ML 모델 성능을 평가합니다.
*본 실습에서는 사이킷런 버전은 1.0.2를 사용하겠습니다.
사이킷런의 모듈명은 from sklearn.으로 시작합니다.
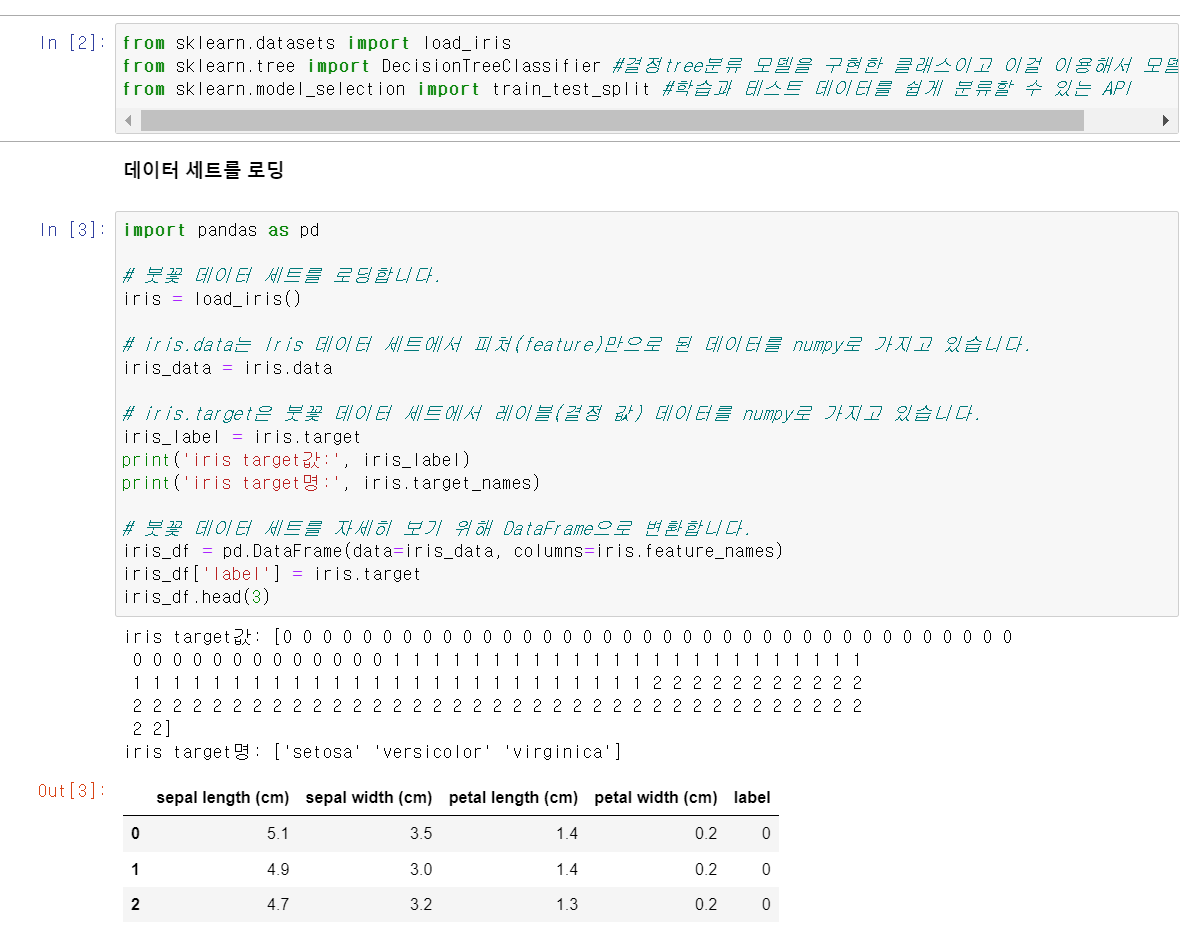
load_iris()를 하면 반환되는 것은 붓꽃 데이터 세트를 반환합니다. iris = load_iris()를 하고 iris.data는 feature 데이터들을 가지고 있습니다. 이처럼 iris.data는 iris 데이터 세트에서 피처의 형태만으로 된 데이터를 numpy 형태로 가지고 있습니다.
iris.targt은 레이블값(결정 값)을 의미합니다.
DataFrame으로 시각화를 시키면 data = iris.data, columns = iris.feature_names 를 pd.DataFrame의 인자로 넣어줍니다.
이후 label이란 이름의 column을 하나 추가합니다.
이제 학습 데이터와 테스트 데이터 세트로 분리하는 작업을 하는데 train_test_split에서 함수 인자를 iris_ata, iris_label로 앞에 받는 것은 feature 데이터 값이랑, test 데이터 값을 받는다는걸 의미하고 test_size=0.2라는 것은 전체 데이터가 예를 들어 150개 일 때 그것의 20%인 30개만을 test 데이터로 쓰겠다라는 뜻입니다.
이를 분리하여서 X_train(학습 feature 데이터 세트) , X_test(테스트 feature 데이터)세트, y_train(학습 target값), y_test(테스트 target값)로 분류가 됩니다.
보통 변수명을 할 때 대문자 X는 Feature, 소문자 y는 target값이다라는게 관습적으로 쓰입니다.
이제 학습 데이터 세트로 학습(Train)을 수행을 하는데있어 우리가 적용해야할 머신러닝 알고리즘인 DecisionTreeClassifier을 생성합니다. 인자로 random_state=11로 실행시킬때마다 고정적으로 결과를 내도록 설정해줍니다. 이를 dt_clf라는 객체로 받았습니다.
학습 데이터 세트로 학습(Train)수행
이후에 학습 수행하는데 fit 처리를 해주는데 이때 인자로 학습용 feature 데이터세트와 학습용 target 값 입니다.
(문제를 주고 답을 주고의 반복과정=> 모델 학습)
테스트 데이터 세트로 예측(Predict)수행
predict할 때는 답을 넣어주면 안됩니다. 따라서 target값을 넣지않고 문제만 넣겠습니다. 그래야 답을 예측할 수 있기때문에 우리가 만든 객체 dt_clf에 predict라는 메소드를 호출합니다. 그리고 거기에 들어가야할 것은 X_test(테스트 feature 데이터세트)입니다.
이후 pred를 수행하게 되면 어떤 결과값을 예측했는지 output으로 확인할 수 있습니다.
그리고 예측 수행한 것을 정확도 평가를 하기 위해서 accuracy_score이라는 답이 맞았는지 틀렸는지 확인할 수 있게 해주는 API를 사용합니다. 인자로 y_test(실제 테스트 target값)과 pred(우리가 예측한 것)을 넣어서 비교합니다.

'머신러닝 공부' 카테고리의 다른 글
| 사이킷런 프레임워크(fit, predict) 와 K-Fold (0) | 2023.02.05 |
|---|---|
| Pandas (판다스) - Index (0) | 2023.02.04 |
| Pandas(판다스) - DataFrame (0) | 2023.02.04 |
| Pandas(판다스) - value_counts method (0) | 2023.02.03 |
| 판다스(pandas) - 기본 API (2) (0) | 2023.02.03 |



