lec 9-1 : XOR 문제 딥러닝을 풀기 (Neural Nets(NN))
XOR 문제를 풀기 위해서는 가장 기본적인 unit 하나로는 풀 수 없는 상태였습니다.
하지만 여러개가 합친 logistic이라면 문제를 풀 수 있게 됐습니다. 하지만 복잡한 Network에 들어가 있는 각각의 weight과 bios는 학습하는게 불가능할 것이라는 이야기도 나왔습니다.
이를 NN을 이용해서 XOR 문제를 해결해보도록 하겠습니다.
| XOR | 0 | 1 |
| 0 | - | + |
| 1 | + | - |
위와 같이 XOR의 성질에 따라 Linear하게 +,-을 구분하는 것은 불가능했습니다. (선 하나를 그어서 +,- 구분은불가능)
이와 같은 상황을 3개의 network을 가지고 해결해보겠습니다.
input에는 2개의 값을, output은 1개의 값을 가진 logistic 3개를 만들어줍니다. 그리고 안쪽 모듈의 연산은 wx+b형태로 만들어줍니다.

다음과 같은 logistic에 gate 연산과정은 wx+b로 해주며 이때 임의로 w와 b를 각각 지정해서 넣어주겠습니다.

이후 우리가 아는 x1,x2 input을 통해서 XOR 문제를 해결해보겠습니다.

다음과 같이 대표 예시를 하나 들어 계산해보며 sigmoid 함수의 결과를 이용해서 XOR 출력 값을보면 다음과 같습니다.
이렇듯 3개의 network를 통해서 XOR 문제를 해결할 수 있었습니다. 해결과정에서 본 방식으로는 2개의 연산과정에서 나온 output y1,y2를 다시 input으로 쓰여 연산을 한 번 더 진행한 과정으로 다음과 같이 볼 수 있습니다.

이와 같은 방법에서 앞의 연산과정을 하나로 줄이고 싶어 우리가 w1,w2 행렬을 합치고 b1,b2도 합쳐서 하나의 연산과정으로 포함시켜 그 output을 K(x)라는 값으로 만들고 앞의 과정을 반복한다면 다음과 같이 나타낼 수 있습니다.
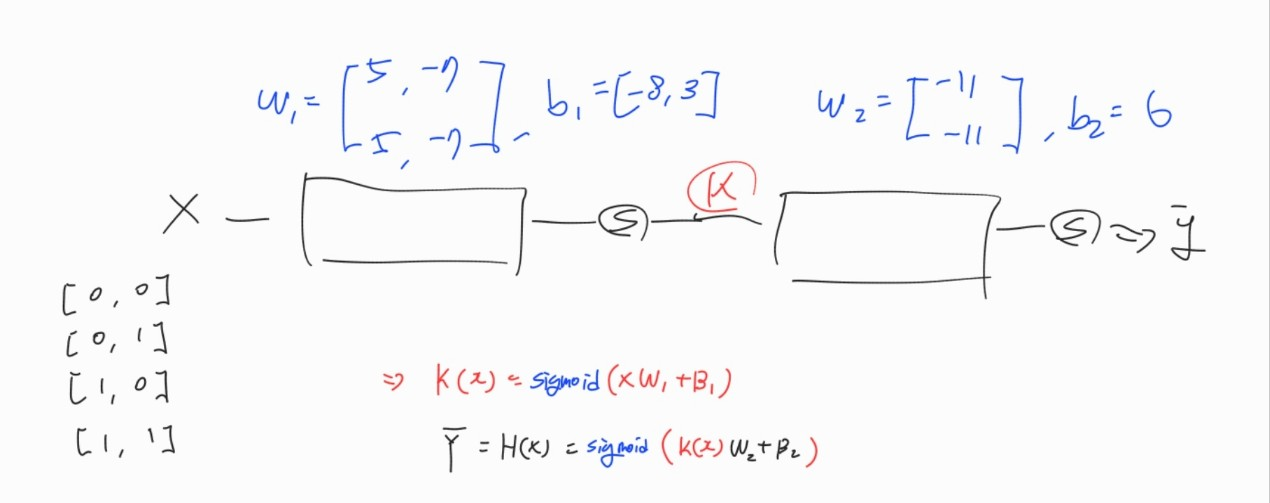
이 처럼 3개의 units을 통해 풀었던 문제를 다음과 같이 2개의 unit을 통해 간소화를 시켜 문제를 풀 수 있었습니다.
하지만 우리가 weight를 준 값과 bios를 준 임의의 값을 어떻게 정할 수 있는지 학습시켜서 weight랑 bios값을 정해질 수 있을까? 라는 고민을 해보겠습니다.
deep network 학습시키기 (backpropagation)
우리가 weight와 bios를 어떻게 기계적으로 학습시킬건지 확인해보겠습니다.
앞서 본 network에서 나오게된 최종 output 값인 y가 어떤 cost함수를 정의할 때 Gradient desent 함수의 모양으로 생긴다면, weight의 값에 따른 y의 값의 모양에서 기울기를 잡아 기울기를 줄이는 방향으로 weight를 계속해서 수정할때 특정 weight값에서 기울기가 0이 되는데 이때 최종적으로 global minimum에 도착하고 이때 cost를 최소화 할 수 있는 방법입니다. 따라서 이 알고리즘을 적용하기 위해서는 미분을 계산해야합니다.
어떤 출력값과 우리가 예측한 값과 비교를 해서 거기서 나오는 오류 cost형태로 되는 것을 output에서 input방향으로 뒤로 미분값과 어떻게 weight를 조정해야하는지 계산하는 알고리즘을 Backpropagation이라고 합니다.
여기서 각 노드나 레이어가 가지고 있는 변수들은 다 제 각각인데 그 값들을 얼만큼 변경하는지 어떻게 알 수 있는지 궁금했다면 이 문제들은 Chain Rule이라는 법칙을 통해 해결할 수 있다고 합니다.
Chain Rule은 미분의 연쇄법칙이라고 불리는 법칙입니다.

앞에서본 예시를 기준으로 위와 같은 Chain Rule을 시각화해서 보겠습니다.
함수 f,g를 왼쪽 위와같이 정리를 해주고 w,x,b를 각각 임의의 수를 넣어 보겠습니다.

Chain Rule을 편미분을 이용한 값을 이용해 다음과 같은 도함수를 얻고 이를 통해 하나의 unit을 최적화하기 위해서 Forward Propagation에서 엄청난 연산량을 Back Propagation에선 편미분값을 구해서 '한번의 곱셈'으로 간단하게 구할 수 있다는 점입니다.
다음에서는 w가 1이 올라갈 때마다 f는 5가 올라가고, x는 1이 오를때마다 f는 2가 감소하는 것을 알 수 있습니다.
위와 같은 방식을 통해서 나머지의 모든 Unit의 Cost 미분값을 간단하게 구하여서 NN을 최적화시킬 수 있습니다.
이를 통해서 우리가 알고있는 Sigmoid 함수도 다음과 같은 Back Propagation을 통한 Chain Rule을 이용하여 미분방정식도 구할 수 있습니다.

'Deep Learning > 모두를 위한 딥러닝 1' 카테고리의 다른 글
| RNN, Recurrent Neural Network (0) | 2023.02.13 |
|---|---|
| CNN, Convolutional Neural Network (0) | 2023.02.13 |

