
Fully Connected Layer 만으로 구성된 인공 신경망의 입력 데이터는 1차원 형태로 한정됩니다. 한 장의 컬러사진은 3차원 데이터 입니다. 배치 모드에 사용되는 여러장의 사진은 4차원 데이터입니다. 사진 데이터로 FC(Fully Connected) 신경망을 학습시켜야 할 경우에, 3차원 사진 데이터를 1차원으로 평면화시켜야합니다. 사진 데이터를 평면화 시키는 과정에서 공간 정보가 손실될 수밖에 없습니다. 결과적으로 이미지 공간 정보 유실로 인한 정보 부족으로 인공 신경망이 특징을 추출 및 학습이 비효율적이고 정확도를 높이는데 한계가 있습니다. 이미지의 공간 정보를 유지한 상태로 학습이 가능한 모델이 CNN입니다.
CNN은 기존 FNN와 비교하여 다음과 같은 차이점이 있습니다.
- 각 레이어의 입출력 데이터 형상 유지
- 이미지 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식
- 복수의 필터로 이미지의 특징 추출 및 학습
- 추출한 이미지의 특징을 모으고 강화하는 Pooling Layer
- 필터를 공유 파라미터로 사용하기 때문에, 일반 인공 신경망과 비교하여 학습 파라미터가 매우 적음
CNN은 위의 이미지와 같이 이미지를 추출하는 부분과 클래스를 분류하는 부분으로 나눌 수 있습니다. 특징 추출 영역은 Convolution Layer와 Pooling Layer를 여러 겹 쌓는 형태로 구성됩니다. Convolution Layer는 입력 데이터에 필터를 적용 후 활성화 함수를 반영하는 필수 요소입니다. Convolution Layer 다음에 위치하는 Pooling Layer는 선택적 레이어입니다. CNN 마지막 부분에는 이미지 분류를 위한 Fully Connected 레이어가 추가됩니다. 이미지의 특징을 추출하는 부분과 이미지를 분류하는 부분 사잉에 이미지 형태의 데이터를 배열 형태로 만드는 Flatten 레이어가 위치합니다.
CNN은 이미지 특징 추출을 위하여 그림과 같이 입력데이터를 필터가 순회하며 convolution을 계산하고, 그 결과를 이용하여 Feature map을 만듭니다. Convolution Layer는 Filter의 크기, Stride, Padding 적용여부, Max Pooling 크기에 따라서 출력 데이터의 Shape이 변경됩니다.
용어
- Convolution (합성곱)
- Channel
- Filter
- Kernel
- Stride
- Padding
- Feautre Map
- Activation Map
- Pooling Layer
Convolution
합성곱이라는 사전적 정의입니다. convolution은 처음 등장한 개념은 아니라 이미지처리에 사용되었던 개념입니다.

빨간 박스는 필터가 적용될 영역이고 개발자의 임의로 한칸씩 이동시키면서 적용시킬건지, 두칸씩 이동할건지 정할 수 있습니다. (이 값을 stride라고 합니다.)
이를 통해 이미지의 feature map을 만들 수 있습니다. filter(또는 kernel)의 구성에 따라 이미지의 특징을 뽑을 수 있습니다
Channel
이미지 픽셀 하나하나는 실수입니다. 컬러 사진은 천연색을 표현하기 위해서, 각 픽셀을 RGB 3개의 실수로 표현한 3차원 데이터입니다. 다음 컬러 이미지는 3개의 Channel로 구성이됩니다. 반면에 흑백 명암만을 표현하는 흑백 사진은 2차원 데이터로 1개 채널로 구성됩니다. 높이가 39, 폭이 31 픽셀인 컬러 사진 데이터의 shape은 (39,30,3)입니다. 반면에 흑백사진이고 높이랑 폭은 앞과 같은 픽셀의 수라면 shape은 (39,30,1)입니다.

Filter & Stride
필터는 이미지의 특징을 찾아내기 위한 공용 파라미터입니다. Filter를 Kernel이라고하기도 합니다. CNN에서 Filter와 Kernel은 같은 의미입니다. 필터는 일반적으로 (4,4),(3,3)와 같이 정사각 행렬로 정의됩니다. CNN에서 학습의 대상은 필터 파라미터입니다. 다음 그림과 같이 입력 데이터를 지정된 간격으로 순회하며 채널별로 합성곱을 하고 모든 채널(컬러의 경우는 3개)의 합성곱의 합을 Feature Map으로 만듭니다. 필터는 지정된 간격으로 이동하면서 전체 입력데이터와 합성곱하여 Feature Map을 만듭니다. 다음그림은 채널이 1개인 입력 데이터를 (3,3) 크기의 필터로 합성곱하는 과정입니다.
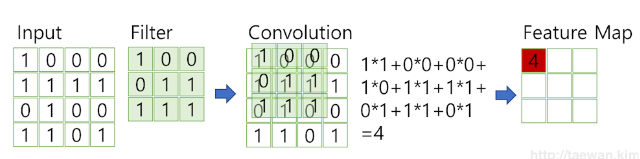
필터는 입력 데이터를 지정한 간격으로 순회하면서 합성곱을 계산합니다. 여기서 지정된 간격으로 필터를 순회하는 간격을 Stride라고 합니다. 다음 그림은 Stride가 1로 필터를 입력 데이터에 순회하는 예제입니다. Stride가 2로 설정되면 필터는 2칸씩 이동하면서 합성곱을 계산합니다.

입력 데이터가 여러 채널을 갖을 경우 필터는 각 채널을 순회하며 합성곱을 계산한 후, 채널별 Feature Map을 만듭니다. 그리고 각 채널의 Feature Map을 합산하여 최종 Feature Map으로 반환합니다. 입력 데이터는 채널 수와 상관없이 필터 별로 1개의 Feature Map이 만들어집니다.

하나의 Convolution Layer 크기에 같은 여러 개의 필터를 적용할 수 있습니다. 이 경우에 Feature Map에는 필터 개수 만큼의 채널이 만들어집니다. 입력데이터에 적용한 필터의 개수는 출력 데이터인 Feature Map의 채널이 됩니다.
Convolution Layer의 입력 데이터를 필터가 순회하며 합성곱을 통해서 만든 출력을 Feature Map또는 Activation Map이라고 합니다. Feature Map은 합성곱 계산으로 만들어진 행렬입니다. Activation Map은 Feature Map행렬에 활성 함수를 적용한 결과입니다. 즉 Convolution 레이어의 최종 출력 결과가 Activation Map입니다.
Padding
Convolution 레이어에서 Filter와 Stride 작용으로 Feature Map의 크기는 입력데이터보다 작습니다. Convolution 레이어의 출력 데이터가 줄어드는 것을 방지하는 방법이 Padding 입니다. Padding은 입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣는 것을 의미합니다. 보통 패딩 값으로 0을 채웁니다.

다음 그림은 (32,32,3) 데이터를 외각에 2 픽셀 추가하여 (36,36,3) 행렬을 만드는 예제입니다. Padding을 통해서 Convolution 레이어의 출력 데이터의 사이즈를 조절하는 기능이 외에, 외각을 '0'값으로 둘러싸는 특징으로 인공 신경망이 이미지의 외각을 인식하는 학습 효과도 있습니다.
Pooling 레이어
Pooling layer는 Convolution layer의 출력 데이터를 입력으로 받아들여 출력 데이터의 크기를 줄여주거나 특정 데이터를 강조하는 용도로 사용합니다. 풀링 레이어를 처리하는 방법으로는 Max Pooling과 Average Pooling, Min Pooling이 있습니다. 정사각 행렬의 특정 영역 안에 값의 최대값을 모으거나 특정 영역의 평균을 구하는 방식으로 동작합니다. 밑의 그림은 Max Pooling 과 AVerage Pooling의 동작방식을 설명합니다.

Pooling 레이어는 Convolution 레이어와 비교하여 다음과 같은 특징이 있습니다.
- 학습대상 파라미터가 없음
- Pooling 레이어를 통과하면 행렬의 크기가 감소
- Pooling 레이어를 통해서 채널 수 변경 없음
CNN에서는 보통 Max Pooling을 사용합니다.
CNN구성
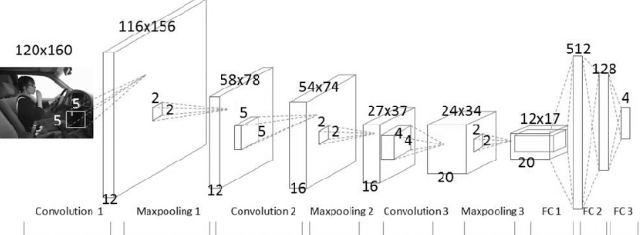
다음그림은 전형적인 CNN구성입니다. Convolution Layer와 Pooling 레이어를 반복적으로 stack을 쌓는 Feature Extraction부분과 Fully Connected Layer를 구성하고 마지막 출력층에 Softmax를 적용한 분류 부분으로 나뉩니다.
CNN을 구성하면서 Filter,Stride, Padding을 조절하여 Feature Extraction 부분의 입력과 크기를 계산하고 맞추는 작업이 중요합니다.
CNN(Convolution Neural Network)은 이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식하고 강조하는 방식으로 이미지의 특징을 추출하는 부분과 이미지를 분류하는 부분으로 구성됩니다. 특징 추출 영역은 Filter를 사용하여 공유 파라미터 수를 최소화하면서 이미지의 특징을 찾는 Convolution 레이어와 특징을 강화하고 모으는 Pooling레이어로 구성됩니다.
CNN의 Filter의 크기, Stride, Padding과 Pooling 크기로 출력 데이터 크기를 조절하고, 필터의 개수로 출력 데이터의 채널을 결정합니다.
CNN는 같은 레이어 크기의 Fully Connected Neural Network와 비교할 때, 학습 파라미터양은 20%규모입니다. 은닉층이 깊어질 수록 학습 파라미터의 차이는 더 벌어집니다. CNN은 Fully Connected Neural Network와 비교하여 더 작은 학습 파라미터로 더 높은 인식률을 제공합니다.
'Deep Learning > 모두를 위한 딥러닝 1' 카테고리의 다른 글
| RNN, Recurrent Neural Network (0) | 2023.02.13 |
|---|---|
| lec 9장 (0) | 2023.02.07 |

